· Abraham · Alyss AI · 3 min read
Arquitectura de Alyss AI
Explorando la evolución hacia una arquitectura modular, los retos de la latencia y la integración de LangGraph, MCP y SGLang.
Llevo ya unas cuantas pruebas de concepto viendo cómo podría ser la arquitectura del proyecto, la estructura de carpetas y cómo iba a fluir el código. Y creo que estoy listo para intentar la primera versión 1.0.0; y si sale mal, no nada, la tiramos abajo y volvemos a empezar. :)
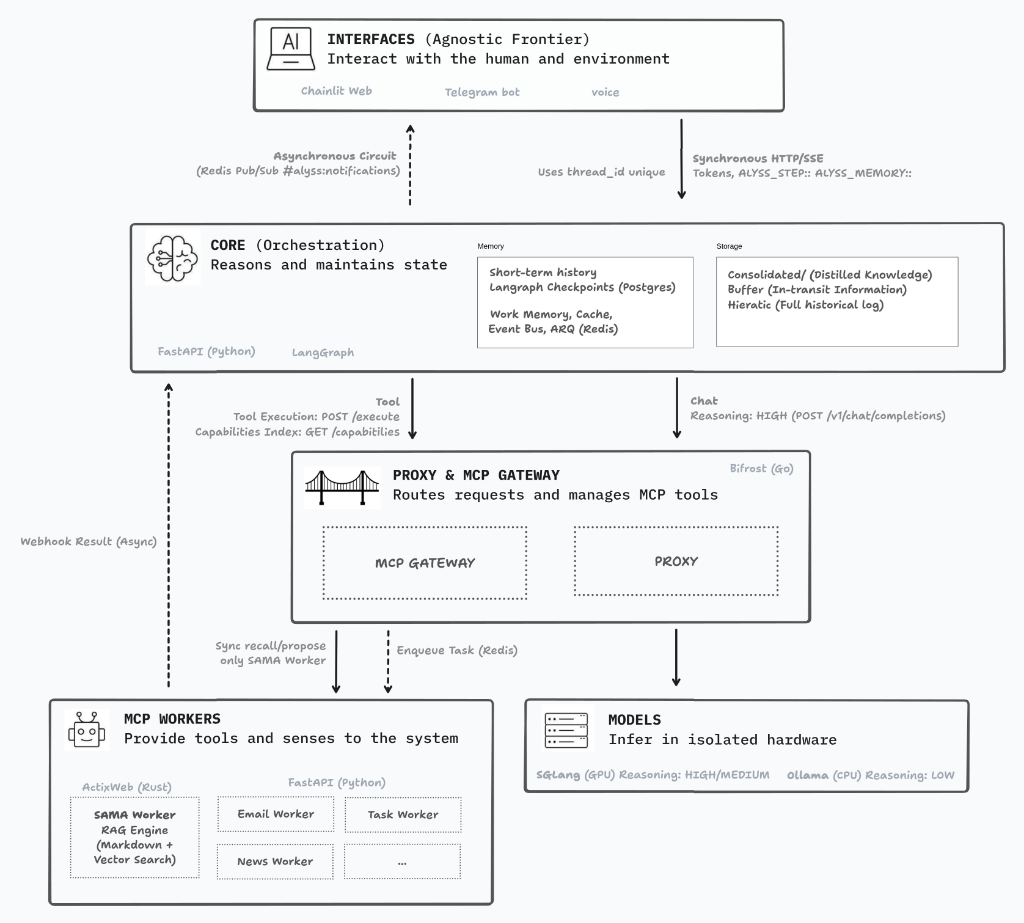
En el diagrama de arquitectura he optado por un ecosistema muy modularizado. Lo que más me preocupa de este enfoque (aparte de que sea consistente y esté alineado con los estándares) es la latencia. La idea de que todo esté dockerizado facilita enormemente el despliegue, mantenimiento y crecimiento del sistema, pero tantas capas y contenedores inevitablemente van a añadir latencia.
Siempre está la eterna duda: ¿hacer un monolito, que es más eficiente a nivel de ejecución local, o apostar por capas desacopladas para poder distribuirlo a futuro entre varias máquinas? Al final, me he decantado por lo segundo, pero aplicando decisiones estratégicas en cada capa para intentar mitigar ese retraso.
El Cerebro y las Interfaces
En mis primeras pruebas con la interfaz Chainlit, me ha parecido un framework fabuloso. Permite personalizar la experiencia al gusto, con flujos de decisión y streaming de tokens en tiempo real. No es perfecto; hay alguna cosa que no me ha convencido del todo, pero igual es desconocimiento mío por ahora.
Para el “Core” u orquestador, LangGraph me resulta cada vez más cómodo. Mantener esta capa en Python tiene todo el sentido del mundo porque los LLM razonan con mayor precisión sobre lógica y esquemas expresados en Python, además de darme muchísima flexibilidad para iterar rápido en la personalidad y los flujos de decisión de Alyss AI.
Bifrost y los MCP Workers
Una primera versión que probé exponía mis tools directamente a LangGraph. Funcionaba bien, pero devoraba contexto y mi hardware es limitado. Ahora voy a apostar por un enfoque basado en MCP (Model Context Protocol) usando Bifrost como gateway.
Bifrost permite hacer de gateway y proxy para los modelos y de orquestador para las herramientas. La idea es que LangGraph ya no necesita tragarse los esquemas gigantescos de todas las herramientas; Bifrost le pasa un índice comprimido, lo que ahorra un consumo masivo de tokens. Además, que Bifrost esté escrito en Go promete una baja latencia de red. En mis pruebas usaba como proxy LiteLLM, pero con Bifrost puedo unificarlo todo; así que mucho mejor y espero que sea más rápido.
La sala de máquinas: Ollama y SGLang
Por último, el hardware. Por ahora dispongo de una 3080 con 12 GB, lo cual es un reto y bastante limitado. Siempre he usado Ollama en diferentes proyectos personales y en esta arquitectura seguirá teniendo su lugar, pero lo voy a relegar a ejecutar modelos ligeros en la CPU para tareas sencillas de los workers (como formatear o tomar decisiones simples).
Para mí la novedad es SGLang. Lo voy a usar como el runtime principal corriendo en la GPU. ¿El motivo? En una gráfica con memoria limitada como la mía, gestionar la VRAM es crítico. SGLang utiliza RadixAttention, lo que significa que “cachea” los prompts del sistema y las definiciones de herramientas. Al no tener que reprocesar esos tokens comunes en cada turno, promete respuestas muchísimo más rápidas (Time To First Token). Puedes ver los resultados de rendimiento en mi reciente artículo de benchmarks.
A esto le sumamos el SAMA Worker, que se encargará del RAG y la búsqueda vectorial para que la memoria de Alyss AI sea sólida.
Ya os contaré qué tal se comporta todo este stack. :)



