· Abraham · Alyss AI · 3 min read
Ollama, vLLM, or SGLang?
I just couldn't resist testing it for myself on my RTX 3080 12GB.

Nowadays, it’s incredibly easy to just ask an AI: “Hey, what’s going to run better on my RTX 3080 12GB: Ollama, vLLM, or SGLang?” In a split second, you get a theoretical dissertation on first-token latency, context windows, paged attention, and a dozen other buzzwords.
You’re left thinking: “Okay, but when you say ‘much better,’ exactly how much are we talking about?” Because it wouldn’t be the first time that “much better” turns out to be a handful of milliseconds in exchange for a massive setup headache that ruins your afternoon.
Since I wasn’t sold on those vague, broad estimates, the temptation to test it myself was too strong to ignore. I’ve set up a fair fight: same model (Qwen 2.5 7B), same quantization (AWQ), and the three engines head-to-head.
The Test Bench
To make sure this wasn’t just firing off a single prompt and calling it a day, I designed 4 specific tests:
- Deep Context: I fed it the actual technical documentation for my project (about 1,200 words). Let’s see how it “reads.”
- Cold Start Inference: Measuring the Time To First Token (TTFT) with a fresh prompt—no tricks, no cache.
- Prefix Caching (Hot Cache): Sending the exact same document a second time. This reveals who’s actually smart enough to use caching (Radix Cache) to avoid re-reading what it already knows.
- Throughput Stress: Forcing the model to spit out exactly 100 tokens. This measures the raw “writing” horsepower of the GPU (Tokens Per Second).
After some wrestling—especially with SGLang’s configuration—here are my final numbers:
| Engine | Interactivity (TTFT) | Speed (TPS) |
|---|---|---|
| SGLang | 0.66 s | 144.9 TPS |
| vLLM | 0.64 s | 139.1 TPS |
| Ollama | 1.69 s | 131.7 TPS |
Detailed Results
- vLLM (Marlin Optimized)
- Point 1 (Deep Context): Handles 2k tokens with total fluidity.
- Point 2 (Cold Start - TTFT): 0.64 s (Very agile).
- Point 3 (Hot Cache - TTFT): 0.02 s (Instant cache).
- Point 4 (Throughput - TPS): 139.1 TPS.
- SGLang (Marlin + CUDA Graphs)
- Point 1 (Deep Context): Full 2k token capacity.
- Point 2 (Cold Start - TTFT): 0.66 s (Excellent interactivity).
- Point 3 (Hot Cache - TTFT): 0.15 s (Very efficient cache).
- Point 4 (Throughput - TPS): 144.9 TPS (The fastest).
- Ollama-GPU (GGUF Q4_K_M)
- Point 1 (Deep Context): Correct, but suffers in the initial load.
- Point 2 (Cold Start - TTFT): 1.69 s (Almost 3 times slower than SGLang).
- Point 3 (Hot Cache - TTFT): 0.06 s (Effective cache).
- Point 4 (Throughput - TPS): 131.7 TPS.
The differences aren’t earth-shattering, especially between SGLang and vLLM on my specific hardware, but as long as I don’t run into any unexpected bugs, I’m sticking with SGLang.
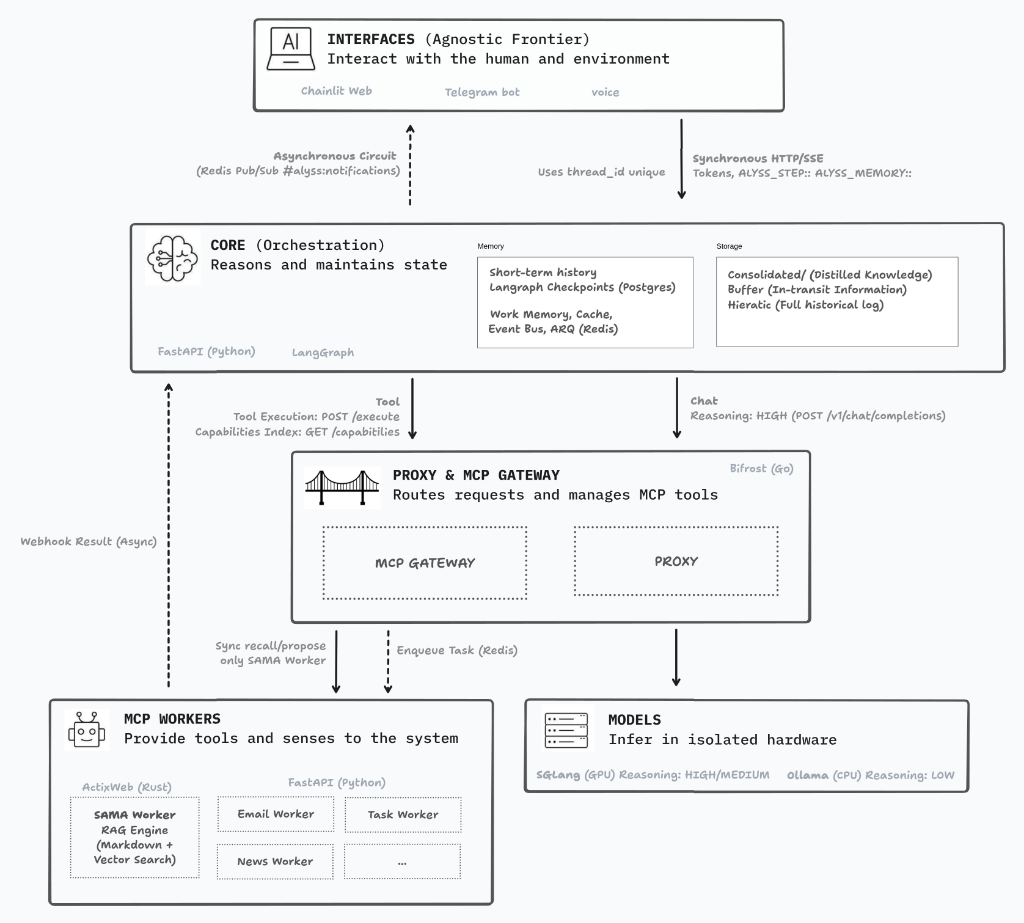
In upcoming posts, I’ll dive deeper into how these metrics impact the final architecture of Alyss AI.
Author's Note: English is not my mother tongue. While I lean on digital tools for translation, I personally oversee every word to ensure that the human intent and the original soul of my Spanish writing remain intact. This is a journey of ideas, not just algorithms.